Last updated: 27.01.2022
| Short introduction: Data is an indispensable element for the development of neural networks in Machine learning and more globally in AI. Their characteristics (e.g. quality, quantity, velocity) can impact the performance of the neural network and beyond, the success of an AI project. Why ? Because data contains information (correlated data) that becomes knowledge when a human interprets it. This phenomenon of moving from data to knowledge has been discussed in an article that I co-authored (see citation at the end of this article). I extracted in this article the section of the original article cited at the end, that discuss this matter. |
Target audience: Computer sciences audience, project managers
Keywords: Data, information, Knowledge
Definitions: Data, Information, and Knowledge
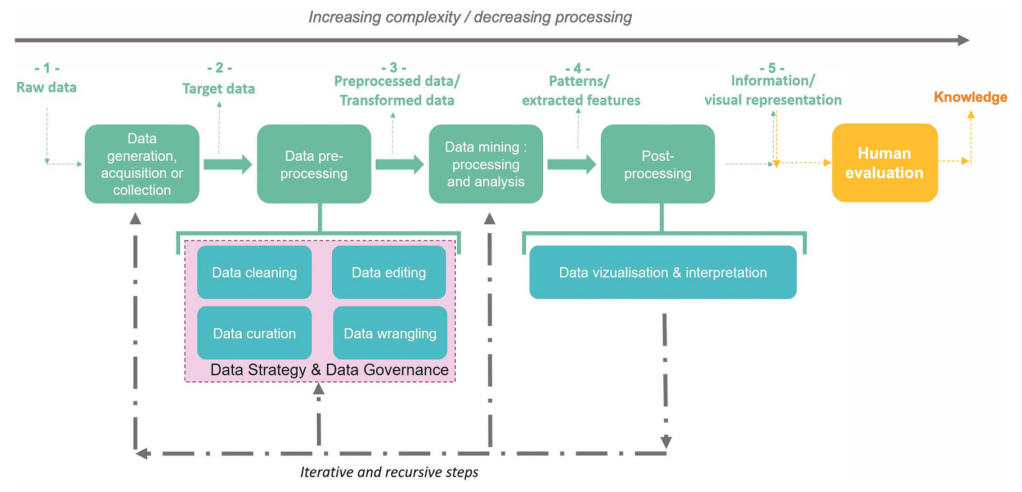
(Grazzini and Pantisano, 2015) defined each concept as follows:
Data can be considered as raw material given as input to an algorithm. Since it cannot be reproduced when lost, it must be carefully preserved and harvested. It can be of different forms: a continuous signal as in the recording of an electroencephalogram (EEG), an image representing a magnetic resonance imaging (MRI), a textual data, or a sequence of numerical values representing a series of physiological measurements or decisions taken via an application. Data can be complete, partial, or noisy. For example, if only a portion of an EEG recording is available, then the data are partial. Conversely, an EEG recording that has been completed but that has some parts unusable is said to be noisy because the noise alters the completeness of the recording. Two types of data can be distinguished: unstructured data, i.e., data directly after their collection or generation, and structured data, i.e., data that have been analyzed, worked on, and put in relation to each other to put them in a format suitable for the analysis considered afterwards. In the second case, it is considered information. Importantly, data by themselves are worthless.
Information is dependent on the original data and the context. If it is lost, it can be reproduced by analyzing the data. Depending on the data processed at time t, information must be accurate, relevant, complete, and available. Information is intelligible by a human operator and can be used in a decision-making process. It is therefore significant and valuable since it provides an answer to a question. It can take various forms such as a text message, a table of numerical values, graphs of all kinds, or even in the shape of a sound signal. When semantics are added to a set of information, it becomes knowledge. Information, depending on the context, will not have the same impact. It is the context and the semantics brought by it and the human operator involved that will determine the value of that knowledge.
To illustrate these definitions in a mental health setting, in the case of a patient undergoing a follow-up with a psychiatrist: the psychiatrist can make his patient pass numerous tests in order to collect data: MRI, EEG, and textual answers to questionnaires. These data, once processed, formatted, and analyzed together, will represent a set of information on the condition of the patient. It is the combination of the knowledge and experience of the doctor, combined with his knowledge of the patient, his family context, and the current socio-economic context, that will enable him to have a global knowledge of his patient and to provide him with the best possible support.
The passage from data to information thus requires a majority of digital processing to highlight correlations according to a given context. However, the passage to the knowledge stage requires
considering individuals involved (see Project design). Figure 4 illustrates data transformation into information through digital processing and into knowledge through human evaluation.
There is thus an increasing complexity in this process of transforming data into information and then into knowledge which makes it difficult to identify and extract.
Knowledge Data extraction in the Litterature
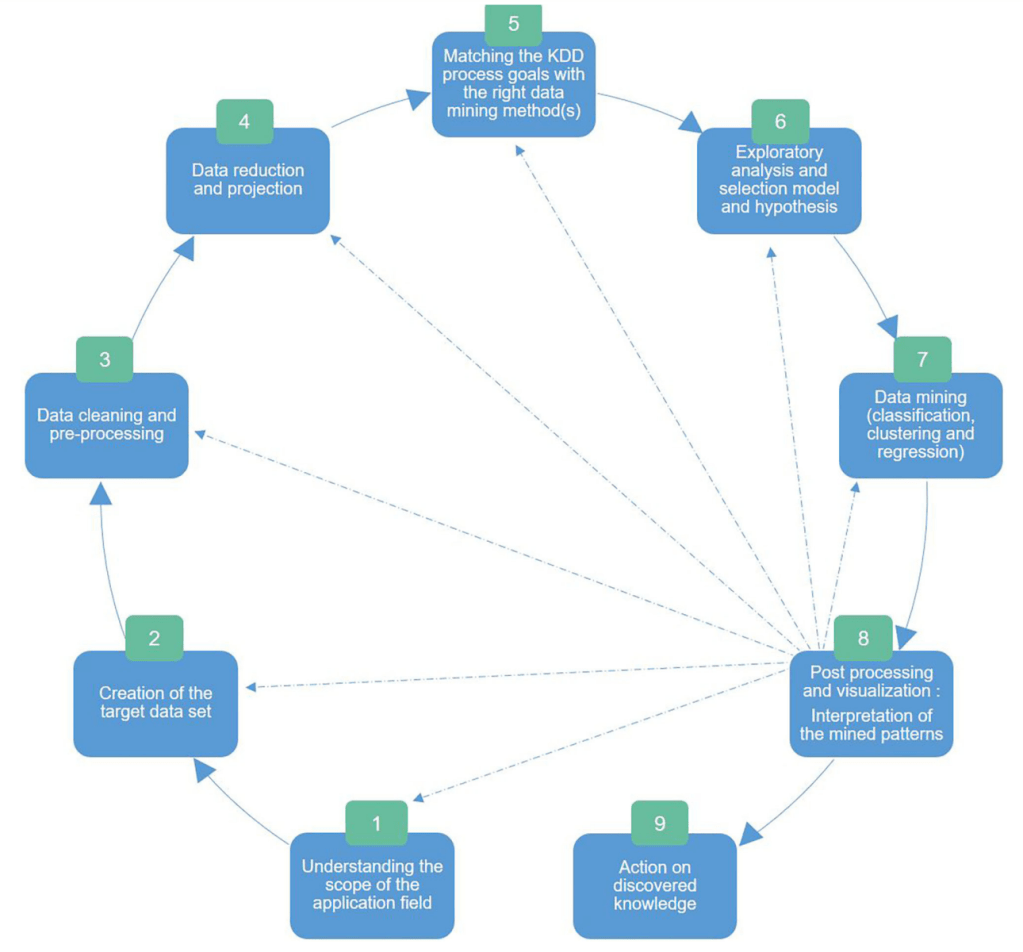
Knowledge Discovery of Data (KDD) is defined as the process of discovering useful knowledge from data (Fayyad, 1996). As a three-step process, the KDD includes (1) a preprocessing step which consists of data preparation and selection, (2) a data mining step involving the application of one or many algorithms in order to extract information (i.e., patterns), and (3) a postprocessing step to analyze extracted information manually by a human operator and lead to knowledge discovery.
As an iterative and interactive process, KDD involves many steps and decisions of the users. Iterations can continue as long as extracted information does not satisfy the decisionmaker (see Identifying cognitive biases in digital health to improve health outcomes).
Concretely, as illustrated in Figure 5, the KDD stages encompass the following: (1) understanding the scope of the application field; (2) creation of the target dataset; (3) data cleaning and preprocessing; (4) data reduction and projection: reducing the number of variables to be analyzed by reducing the dimensionality of the data, extracting invariant representations, or searching for relevant characteristics; (5) matching the goals of the KDD process with the right method(s) in data mining; (6) exploratory analysis and selection model and hypothesis: selection of the data mining algorithm and method that will be used for the pattern search; (7) data mining: searching for interesting patterns in a particular form of representation, which includes rule and tree classification, regression, and clustering; (8) data postprocessing and visualization: interpretation of the patterns found with possible return to any step from 1 to 7 for a new cycle; and (9) action on discovered knowledge.
Here, we mainly focus our approach on the technical aspect, i.e., data and their transformation into information. We aim to present a complete and global approach by covering the KDD stages in the life cycle of a digital health product from the definition of the scientific question to data collection and analysis (for further details, see Appendix 3 in the original article).
To cite this article :
LJ. Boulos, A. Mendes, A. Delmas, I.Chraibi K. An Iterative and Collaborative End-to-End Methodology Applied to Digital Mental Health. Frontiers in Psychiatry, Frontiers, 2021, 12, ⟨10.3389/fpsyt.2021.574440⟩. ⟨hal-03352727⟩
Reference
- Grazzini J, Pantisano F. Guidelines for Scientific Evidence Provision for Policy Support Based on Big Data and Open Technologies (2015).
- Fayyad U, Piatetsky-Shapiro G, Smyth P. From data mining to knowledge discovery in databases. AI Magazine. (1996) 17:37.
