Last updated: 28.08.2020
This article was originally published in french on the Scilog blog related to the magazine “Pour la Science” and on the Blog Binaire, blog of the magazine “Pour la Science”, for scientific popularization.
Target audience: all audiences, high school students
Keywords: Black box, Deep learning, Explainable AI, Artificial Intelligence, Interpretability, machine learning, neural networks, Popularization
| Short introduction: This article is the result of the collaboration of Marine LHUILLIER and myself in 2020. Marine was my intern and we both worked on an explainable AI project. During our collaboration, Marine get specialized in research at the crossroad of AI and Cognitive Sciences. She is now a Research Engineer / Data Engineer. |
As human beings, how can we understand and explain an automated decision made1 with an algorithm from what is called Artificial Intelligence, or AI, (for example a neural network)?
It is more than important to be able to explain and interpret these results, sometimes bluffing or simply counter-intuitive, which often guide our human decisions. This problem has its origins in the very concept of Machine Learning.
| The first of a series of three articles that question the concepts of interpretability and explainability of neural networks, we begin here with an introduction to the problems related to the understanding of these Machine Learning algorithms. |
Machine Learning (ML) is a sub-field of artificial intelligence domain that consists in giving a machine (a computer) a learning capacity without it having been explicitly programmed for this [WhatIs, 2016] and this, by adjusting its calculation according to so-called learning data. In other words, an ML algorithm consists in asking our machine to perform a task without precisely coding the different steps and actions it will have to perform to get there but by adjusting the parameters of a very general calculation to the data provided.
It is precisely these automated decisions, linked to the use of Machine Learning algorithms, especially artificial neural networks, known as deep learning when there are many layers of calculation, that are raising more and more ethical and legal issues [Hebling, 2019]. These problems are mainly due to the opacity of most of these Machine Learning algorithms. They, therefore, lead more and more researchers, developers, companies, and also users of these tools to ask themselves questions about the interpretability and explainability of these algorithms.
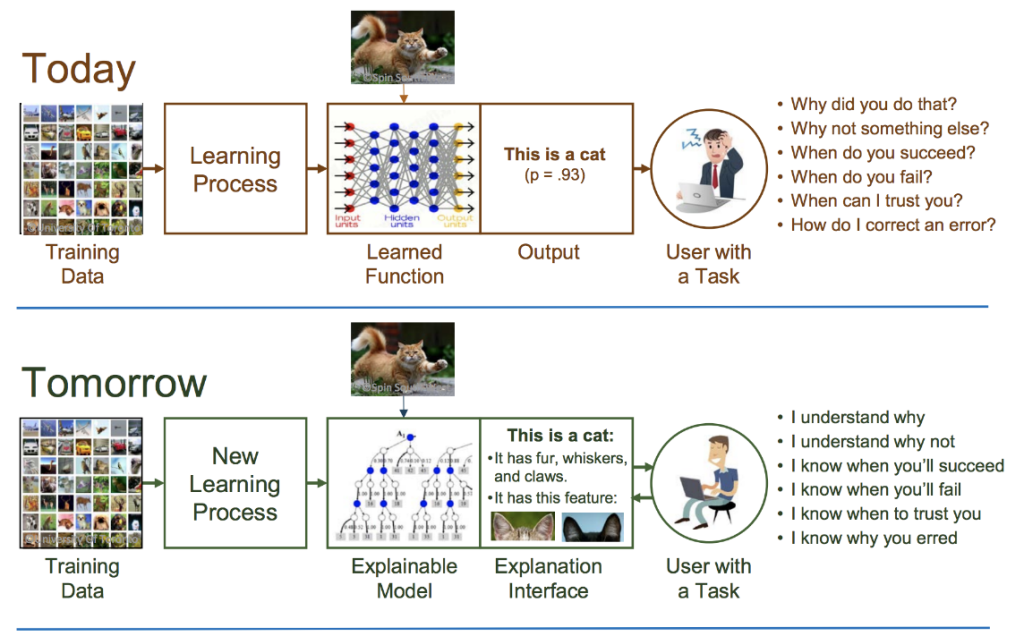
From the black box to explainable AI
“The main difference between the AI of the 1970s and that of today is that it is no longer a purely deterministic approach” [Vérine and Mir, 2019].
Indeed, the implementation of AI algorithms has evolved significantly in recent years. Previously based mostly on the developers’ choices, the arrangement of formulas and mathematical equations used, these algorithms and their decision-making were strongly influenced by the developers, their culture, their own way of thinking. Now, these rules are much more derived from the “hidden” properties in the data from which the algorithms will learn, i.e. adjust their parameters. Of course, the implementation will still be influenced by the developer, but the algorithm’s decision-making will not be as much influenced. As a result, automated decision-making by these algorithms has become opaque.
Thus, today, if a neural network is assimilated to a “black box” it is because the input and output data are known but its internal functioning, specific after learning, is not precisely known. When we study the deep hidden layers of a network (represented on our figure 2 by the darkest frame) we observe that the internal representation of the data is very abstract, and therefore complex to decipher, as are the implicit rules encoded during learning.
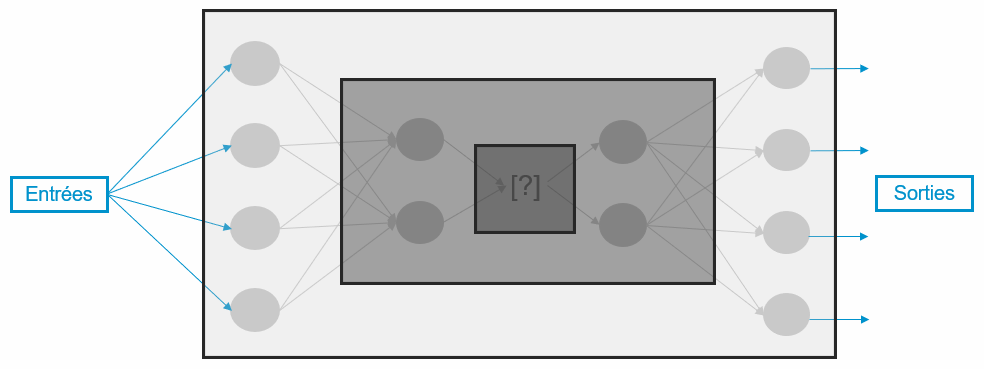
This phenomenon is notably due to the approach that many researchers and developers in AI have had for years: the performance of these algorithms has been put at the center of concerns to the neglect of their understanding.
Let’s also underline another aspect involved in this “black box” phenomenon: the increasing volume of data! Indeed, the volume of data used has exploded in recent years, which was not the case at the beginning of AI. The now gigantic size of the data taken into account by algorithms hinders, if not prevents, the analysis and understanding of their behavior by a human brain. For example, if a person can analyze one or ten receipts simultaneously, it quickly becomes impossible for them to look for similarities in more than a hundred of them to understand and predict the behavior of consumers in a supermarket. This is even more true when thousands or millions of receipts are processed in parallel. This makes it difficult to understand the decisions resulting from the analysis and predictions of these algorithms.
If the demystification of the “black boxes” represented by neural networks has become a major topic in recent years, it is due, among other things, to the fact that these tools are increasingly used in critical sectors such as medicine or finance. It is therefore essential to understand the criteria taken into account behind their decision proposals in order to limit as much as possible, for example, the moral and ethical biases present in these proposals.
Precisely, the decision proposals resulting from AI algorithms raise crucial and general questions, notably in terms of the acceptability of these tools. The need for trust and transparency is thus very present and highly valued. There is therefore today a real reorientation of the problems linked to Machine Learning, particularly the need to explain them [Crawford, 2019].
Indeed, how can we trust the decision proposal of an AI algorithm if we cannot explain where it comes from? The entry into force of the GDPR (in europe), particularly Article 22-1 stipulating that a decision cannot be based exclusively on automated processing, added to the fact that a human needs explicit and non-opaque elements to make a decision, has greatly accelerated research in this area.
Interpretability or explainability?
The need for transparency and confidence in Machine Learning algorithms (e.g. neural networks or reinforcement learning mechanisms) has led to the emergence of two concepts: interpretability and explicability. Often associated, it seems important to clarify that these are two different concepts: let’s define them!
Interpretability consists in providing information representing both the reasoning of the Machine Learning algorithm and the internal representation of the data in a format that can be interpreted by an ML expert or the data. The result provided is strongly linked to the data used and requires knowledge of the data but also of the model [Gilpin et al., 2018].
Explainability, on the other hand, consists in providing information in a complete semantic format that is self-sufficient and accessible to a user, whether he or she is a neophyte or a technophile, and regardless of his or her expertise in Machine Learning [Gilpin et al., 2018]. For example, the job of a researcher will not be explained in the same way to high school students as to computer science students. The jargon used is adapted to concepts shared by those issuing the explanation and those receiving it.
In other words, interpretability answers the question “how” does an algorithm make a decision (what calculations? what internal data? …) while explicability tends to answer the question “why” (what links with the problem at hand? what relations with the application elements? …). Note that interpretability is the first step to be taken in order to achieve explainability. An explainable model is therefore interpretable, but the opposite is not automatically true!
This also explains why many people are working on the interpretability of artificial neural networks. A vast and exciting field of research, which everyone can approach through their own prism, it has seen a veritable explosion in the number of works and publications since the end of 2017 with, in particular, the Explainable AI (XAI) project of DARPA, the U.S. Department of Defense’s research and development agency (Figure 1).
Interpretability and, by extension, explainability, are therefore fast-growing fields in which many current questions are still far from being resolved!
What to remember?
Machine Learning, Deep Learning and therefore neural networks, which are the subfields of AI research, are nowadays of great interest because their impact on our lives is so important. In parallel to improving accuracy and performance, the AI community needs to understand the internal logic and therefore the causes of the decisions made by these algorithms. But how can we be sure of the relevance of a neural network prediction if the reasons behind it are obscure?
Moreover, can we explain or interpret everything? What about decisions coming from very complex contexts requiring large volumes of data where the set of elements is far too vast to be assimilated by a human brain? These open questions are precisely the objective of the research work that tends towards a human understanding of neural networks;
It is therefore with the aim of demystifying these “black boxes” that researchers, companies and users are increasingly interested in the field of interpretability, i.e. the understanding of the internal logic of neural networks, and that of explicability, i.e. the ability to explain the reasons behind a prediction of these same networks;
We will see in the rest of this series of three articles the questions that need to be answered in order to choose between two interpretability approaches to be used according to the use case but also how they help to make AI more transparent and understandable.
1 The expression “decision making” of an algorithm refers here to the decision made by a human following a proposal (i.e. prediction) from this algorithm. It is therefore a decision proposal.
To cite this article:
Lhuillier M and Chraibi Kaadoud I, Interpretability vs explainability: understanding vs explaining one’s neural network (1/3)? Publication on the blog of http://www.scilogs.fr/intelligence-mecanique, August 2020
References :
- Crawford Kate (2019) « Les biais sont devenus le matériel brut de l’IA ». URL : https://www.lemonde.fr/blog/internetactu/2019/10/03/kate-crawford-les-biais-sont-devenus-le-materiel-brut-de-lia/
- Gilpin, L. H., Bau, D., Yuan, B. Z., Bajwa, A., Specter, M., & Kagal, L. (2018). Explaining explanations: An overview of interpretability of machine learning. In 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA) (pp. 80-89). IEEE.
- Helbing, D. (2019). Societal, economic, ethical and legal challenges of the digital revolution: from big data to deep learning, artificial intelligence, and manipulative technologies. In Towards Digital Enlightenment (pp. 47-72). Springer, Cham.
- Turek, M. (2017). DARPA – Explainable Artificial Intelligence (XAI) Program,URL : https://www.darpa.mil/program/explainable-artificial-intelligence
- Vérine, Alexandre et Mir, Stéphan. (2019). L’interprétabilité du machine learning : quels défis à l’ère des processus de décision automatisés ? URL : https://www.wavestone.com/fr/insight/interpretabilite-machine-learning/
- WhatIs, 2016. Machine Learning definition. Publié sur le site WhatIs.com URL : https://whatis.techtarget.com/fr/definition/Machine-Learning

{kind=link}
{kind=link}