Last updated : 20.10.202
This article was originally published in french on the Scilog blog related to the magazine “Pour la Science” and on the Blog Binaire, blog of the magazine “Pour la Science”, for scientific popularization.
Target audience: all audiences, high school students
Keywords: Black box, Deep learning, Explainable AI, Artificial Intelligence, Interpretability, machine learning, neural networks, Popularization
| Short introduction: This article is the result of the collaboration of Marine LHUILLIER and myself in 2020. Marine was my intern and we both worked on an explainable AI project. During our collaboration, Marine get specialized in research at the crossroad of AI and Cognitive Sciences. She is now a Research Engineer / Data Engineer. |
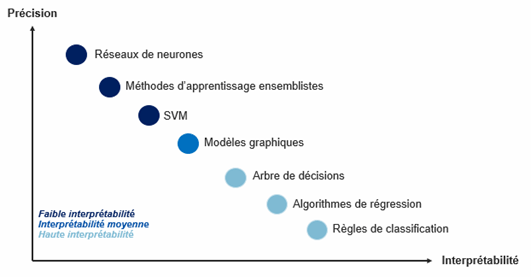
Although artificial neural networks are among the most accurate Machine Learning algorithms, they are currently the most obscure for humans (Figure 1).
| This article is the second in a series of three articles questioning the concepts of interpretability and explicability of neural networks. It provides an overview of existing interpretability approaches according to the objectives sought and attempts to provide some answers to the question “how to open the “black boxes” that are neural networks?” |
Local or global interpretability?
When we talk about the interpretability of artificial neural networks, it is essential to know what we are trying to explain and how we want to use them. Indeed, the techniques that are derived from them are distinguished according to several criteria.
First, it is necessary to know what type of behavior needs to be analyzed. Are we looking for an explanation of the behavior of the whole model or of its behavior on a particular result?
The first approach, called global interpretability, tends to provide an explanation of the global behavior of the network on all the data it has learned. It makes the decision making process transparent for all the data and proves to be a valuable way to evaluate the relevance of what the model has learned [Clapaud, 2019]. On the other hand, local interpretability tends to provide an explanation for a specific outcome, i.e., for a particular decision on a very small scale. It is particularly relevant when it is necessary to analyze a particular case for the needs of a person (patient, client…) for example [Guidotti, 2018].
Let’s illustrate this with an example: Let’s imagine having access to a high-tech microwave oven of which we would have lost the instructions for use, and therefore, of which we were unaware of the operation. We can then always observe the reaction of the microwave when we press the buttons as we go along. By doing this, we associate a result (heated dish) with the arrival of an information (I pressed a particular button). This is what amounts, in fact, to interpreting locally the behavior of the machine (here the microwave oven) according to incoming information since we associate an action and a result through a function. We are then in a dimension of local interpretability:
| In the case of the microwave: Functions of the microwave (heating button pressed) = heated dish. In a more generic case: Functions of a neural network (incoming data at time t) = result/prediction at time t |
The global interpretability corresponds to a simple and global description of the complete functioning of the microwave. In other words, it is a question of outlining its mode of operation: we will know which type of buttons allows defrosting, which type of buttons allows heating, which type of buttons allows adjusting the heating time, etc. But we will not have direct access to the precise behaviors, such as “to defrost a food you must first select the type of food”. But we will not have direct access to precise behaviors, such as “to defrost a food you must first select the type, then the weight, then check the time regularly to reach the desired result1.
In summary, global interpretability allows access to the chapters and main sections of the operating instructions, whereas local interpretability allows access to specific functions of the microwave.
Exploring “a reasoning in progress” or ” a constructed reasoning”?
The second use that is important to determine is to define when the extraction of knowledge from the network will be done.
If the interpretability phase is carried out during the learning of the neural network, it is a pedagogical method because it is possible to observe the behavior of the neural network at several moments during its learning. Indeed, it is admitted that during this stage, the neural network manages to identify and extract characteristics from the data that allow it to adjust itself, i.e. to learn by modifying the weights.
On the other hand, if the extraction is done after learning, i.e. during the test phase, we speak of a decompositional method because in this case, we observe the activity of each hidden layer of the network separately before combining them.
For example, consider a supervised learning task where a network must learn to classify images of turtles and kittens. As it learns, and therefore as it receives examples, this network will identify the characteristics of the images that are specific to each class: pixels, color code, positioning of a set of pixels, etc. Thus, the more examples it processes, the more it will identify these features and the more it will be able to adjust itself to match the right image to the right class.
In this particular case, if we apply a pedagogical method to this network, it is possible to observe the evolution of this feature identification phase at different moments of its learning (for example, every 100 examples presented). In other words, we can observe what it learns and the construction of its “reasoning”.
On the other hand, if we use the decomposition method, we will study the behavior of the neural network (i.e. the activities of the units of the hidden layer(s)) each time it receives a posteriori image of its learning.
At this stage, therefore during the test phase, the network has finished learning and it is possible to extract and analyze its activity at the level of its hidden layers (its behavior or internal activity) in front of each image according to the learning carried out previously. In other words, during this process, we extract individual behaviors from the hidden layers before combining them to obtain the global behavior of the network and thus understand its “reasoning”.
Analyzing a neural network after learning via a decomposition method, therefore, allows us to evaluate its implicit learning by making it explicit.
What to remember ?
If there is only one thing to remember, it is that in terms of interpretability, as in Machine Learning in general, there is not one possible approach but several. Depending on the question we wish to answer (explaining a local or global behavior of the network) and what we wish to understand (how does it learn from the data or how does it make its predictions?) the approach(es) of interpretability of neural networks adopted will be different.
Indeed, it is possible to want to explain or understand the behavior of the network in its totality, i.e. to do global interpretability: what are the set of rules that the network has learned implicitly to classify turtles and kittens? Or on the contrary, we can focus on a specific example by doing local interpretability: why was this specific image classified in this way?
On the same principle, do we seek to understand how the reasoning of the network is built in “real time” or once it is built?
Wishing to answer these questions requires choosing, implementing and/or using the appropriate interpretability technique among the many existing ones. To learn more about this subject, it is possible to explore research areas in Machine Learning such as Representation learning also known as feature learning [Bengio et al, 2013] and Rules Extraction [Jacobson, 2005].
Moreover, questioning the interpretability and explicability of neural networks leads us, as researchers and users of these algorithms, to consider their impact on our daily lives and by extension to questions of ethics and acceptability: are we ready to accept more AI if we have no guarantee of ethics, inclusion and justice? Above all, do we have the means to answer our questions on this subject? These complex relationships between interpretability, bias, ethics and transparency will be precisely presented in the third and last article of this series!
1 Thanks to Frédéric Alexandre, Director of the Mnemosyne team, INRIA Bordeaux, for his help in the elaboration of this “general public” example of local and global interpretability
To cite this article:
Lhuillier M and Chraibi Kaadoud I, Interpretability vs explainability: understanding vs explaining one’s neural network (1/3)? Publication on the blog of http://www.scilogs.fr/intelligence-mecanique, August 2020
References
- Bengio, Y., Courville, A., & Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8), 1798-1828.
- Clapaud, Alain (2019). Explicabilité des IA : quelles solutions mettre en oeuvre ? Publié sur LeMagIT. URL : https://www.lemagit.fr/conseil/Explicabilite-des-IA-quelles-solutions-mettre-en-uvre
- Dam, H. K., Tran, T., & Ghose, A. (2018). Explainable software analytics. In Proceedings of the 40th International Conference on Software Engineering: New Ideas and Emerging Results (pp. 53-56).
- Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Giannotti, F., & Pedreschi, D. (2018). A survey of methods for explaining black box models. ACM computing surveys (CSUR), 51(5), 1-42.
- Jacobsson, H. (2005). Rule extraction from recurrent neural networks: A taxonomy and review. Neural Computation, 17(6), 1223-1263
